手作業で文字コードを復元した話。
古くから稼働しているサーバに、文字化けしていると思われるファイル名を見つけました。このファイルのファイル名を手作業で復元してみました。テキストファイルなので内容を見ればわかるだろう、という突っ込みはご遠慮いただければ幸いです。
問題のファイル名は下記のようになっています。謎解きとしては簡単な方です。
\245\263\245\324\241\274 \241\301 file.txt
円マークの後ろに3桁の数字がくっついているのが8個あります。これが文字コードを表しているようです。
文字コードと思われる文字は、半角スペースによって6個と2個に分けられています。2バイトで1文字を表す文字コードなのかもしれません。
3桁の数字を10進数と仮定して、16進数に変換してみます。Windows10 に標準搭載されている電卓アプリで変換することができます。
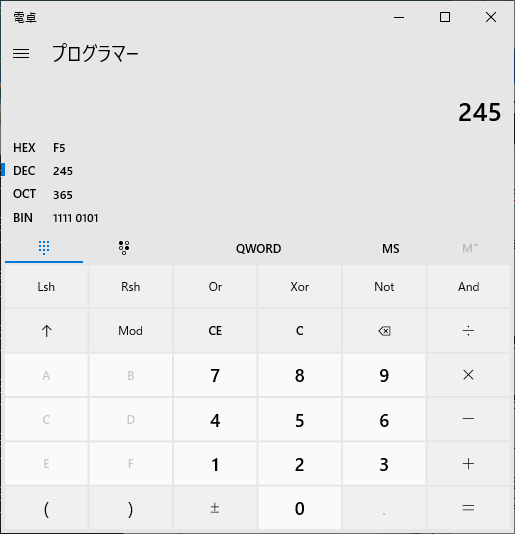
左上のハンバーガーメニュー「三」をクリックして「プログラマー」を選択します。次に「DEC」をクリックして 245 を入力します。そうすると「HEX」のところに変換結果として F5 が表示されます。他の数字も同様にやってみます。
245 → F5 263 → 107 245 → F5 324 → 144 241 → F1 274 → 112 241 → F1 301 → 12D
16進数で3桁の数字が出てきてしまいました。10進数→16進数の変換ではうまく行かないみたいです。(10進数で255を超える数字が存在している時点で気づけよ、という話でもありますが)
3桁の数字を8進数と仮定して16進数に変換してみます。
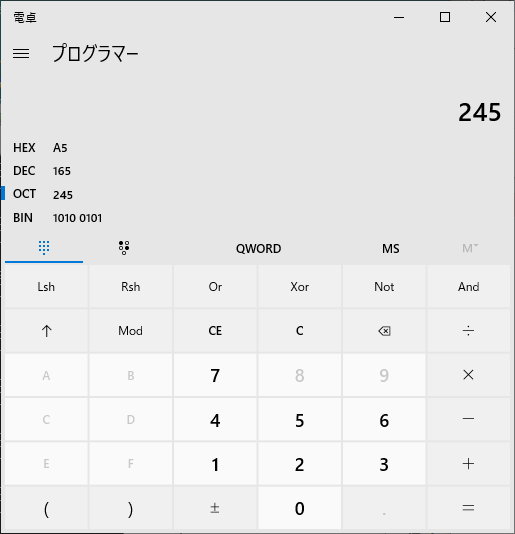
電卓アプリの「OCT」をクリックして数字を入力すると、下記のようになりました。
245 → A5 263 → B3 245 → A5 324 → D4 241 → A1 274 → BC 241 → A1 301 → C1
なんだか文字コードに使われるコードみたいです。SJISの文字コード表に照らし合わせてみます。
文字コード表 シフトJIS(Shift_JIS) http://charset.7jp.net/sjis.html
A5 B3 に該当する文字も、B3 A5 に該当する文字もありませんでした。では、EUC-JPの文字コード表に照らし合わせてみます。
文字コード表 日本語EUC(euc-jp) http://charset.7jp.net/euc.html
A5 B3 のところに文字がありました。「コ」です。
同様に2バイトずつEUC-JPコード表で探してみます。
A5 B3 コ A5 D4 ピ A1 BC ー A1 C1 ~
最終的に、下記のようなファイル名だったことがわかりました。
コピー ~ file.txt
エクスプローラー上でコピー操作を行うと自動的につけられるファイル名だったことがわかりました。
わかってしまえば簡単なことでしたが、ちょっとした謎解きでした。

0件のコメント